

After attending ReactiveConf two weeks ago where JavaScript was the main topic, I switched to the classical backend side of web development by visiting Devoxx in Antwerpen. It is widely seen as one of the best Java conferences.
Numbers speak for themselves: 6,570 proposals, 221 speakers and over 3,500 participants. The conference was held in a large cinema in Antwerpen and lasted 3 days. I looked out for talks specifically covering Java 9 and Spring and wasn’t disappointed at all.
What follows are summaries of my notes from selected talks.
- Mark Reinhold: Moving Java forward faster
- Spring BOF
- Kevin Hennly: Move Slow and Mend Things
- Alex Buckley: Modular Development with JDK9
- Mark Reinhold: Modules in One Lesson
- Daniel Bryant: Continuous Delivery with Containers
- Jürgen Höller: Spring Framework 5 - Themes & Trends
- Brian Goetz: Java Language Futures - All Aboard Project Amber
Mark Reinhold: Moving Java forward faster
Reinhold, the Chief Architect of the Java Platform Group at Oracle, explained the upcoming features of Java and the schedule mode.
Due to the recurring issues with JDK releases being postponed for several years, it was decided to release a new version every half year. Rather than releasing a new version only when all features are completed, one can now publish finished features every release cycle. This will eliminate the situation where a single, uncompleted feature can block a whole release.
The naming convention of the releases will stay as it is. The upcoming version in March 2018 will be Java 10 and half a year later it will be Java 11 and so on.
Like in Ubuntu, every third year the release will have an LTS (long term support) of 5 years. The first one will be Java 11 in September 2018.
The main projects developing Java further have some quite fancy names. There are Panama, Valhalla, Amber and Loom. Amber is very interesting since it is already releasing type inference and pattern matching for Java 10.
Spring BOF
An informal session on Spring took place with a limited number of participants due to the very late hour (8.00pm) of the first day. However, a lot of Spring’s main developers attended.
Most discussion was about the change of Java’s release model and the current module feature in Java 9.
Jürgen Höller, project lead of the core Spring system, mentioned that he sees upcoming issues for library vendors. They are now forced to validate their libraries twice a year. In particular, tools that statically check against the bytecode version could have major problems, since with each release the bytecode version is also increased.
Spring is using ASM and is therefore also affected. Höller mentioned that their strategy is to simply ignore the version of the bytecode. He would encourage every other library vendor to do the same.
There was also a question concerning Kotlin’s support in Spring. Höller said, that they “are going the extra mile” to support Kotlin. He could not predict if Kotlin will become a dominant player. That lies in the hands of the software developers themselves.

Kevin Hennly: Move Slow and Mend Things
Hennly delivered a very abstract keynote during which he talked about various general aspects of software development.
He criticised the trend, where developers blindly follow the famous Facebook motto “Move fast and break things”. This should not mean that one should deliver buggy code. Unfortunately, there are cases where developers actually experience an error in their local environment and still push the code without correction.
Also, the slogan “first to market” is not the always the right goal. Reality shows that the first ones do not always survive. So sometimes it might be good to let others do the hard work, watch them making mistakes and then make it better.
Time is only a proxy metric in project estimations - time does not solve the problem. Somebody has to do the actual work and that is the key thing in development. The hardest part in estimation is the time and effort needed to solve new problems. Since programmers don’t do things twice - they take existing code and reuse it - the best estimations can be made when the new problems are similar to ones already solved.
Code represents a programmer’s understanding of the problem. It can be seen as codified knowledge. It is not the same as production in the sense you would see “production” in producing physical objects. Coding is knowledge acquisition and therefore a programmer should be seen as a knowledge worker.
If a programmer is primarily a knowledge worker then it is also very important, that the whole group shares that knowledge and understanding. In that sense, group intelligence is superior to individual intelligence. Studies show that the group intelligence increases if there is a high degree of diversity. So typical HR actions that recruit people by “company fit” achieves the exact opposite and doesn’t do any good. Another consequence is that, by simply hiring more women, you can very easily increase the diversity in a “typical software development team”.
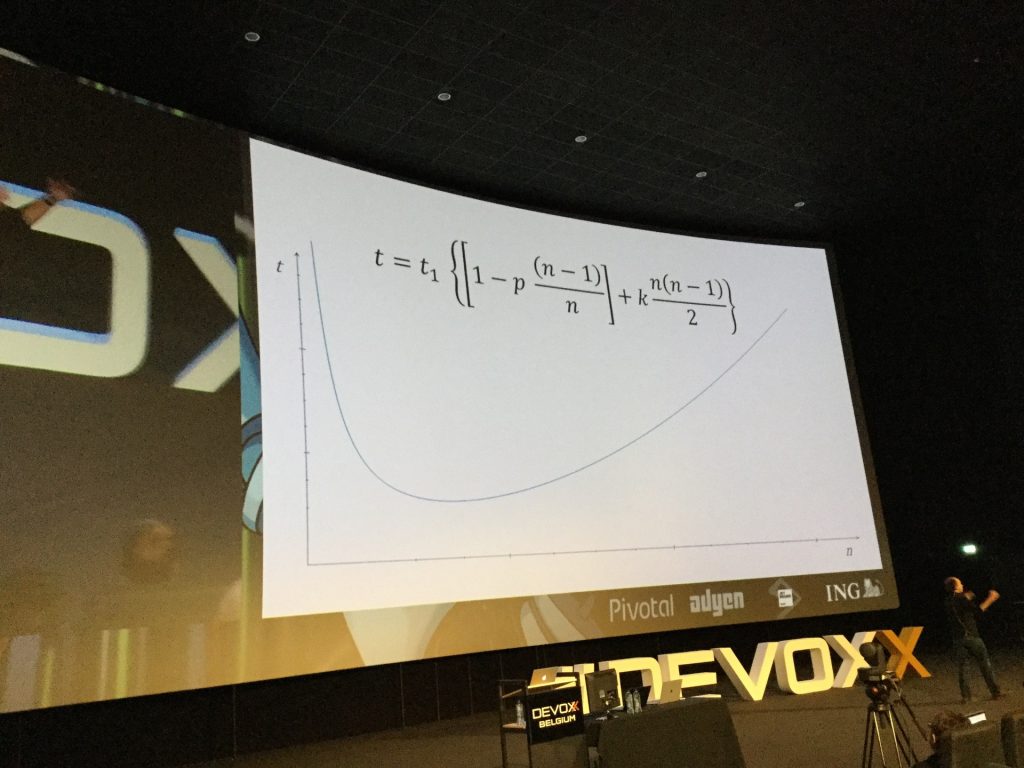
Hennly also called attention to the famous “Silver Bullet”, termed by Fred Brooks. Hennly showed a chart where he could prove that, at a certain team size, the whole code that a team produces is equal to the same amount a single developer could do alone. This is due to the increased communication load of large teams. Unfortunately, since business decision-makers don’t recognise that division of labour does not apply to software development, they try to solve the problem by adding even more people.
He ended his talk with the fact that most of the critical failures could have been detected with normal unit tests.
Alex Buckley: Modular Development with JDK9
JDK 9 introduces the concept of a module that can be used to group packages. Regardless of whether a class is public or not: If it is not part of a package that is exported by a module, it can’t be used by others.
The JDK itself was split up into modules. This was one of the major tasks of the current release. java.base forms the base package that contains java.lang, java.io, java.net and java.util.
One of the major drivers for modularization was to eliminate split packages. This is a package that has its code distributed over various jars. Since one can determine the modules that are actually required, one can now easily reduce the size of an application. This is similar to the concept of tree-shaking we know from JavaScript’s webpack and similar (oops, did I just really write that ;)).
Mark Reinhold: Modules in One Lesson
During a live coding session on Java 9, Mark Reinhold showed how to create a Java 9 module from scratch.
Modules like Jackson that are working with reflection require more privileges. There is an option that grants only these specific modules full access via reflection.
The file that contains the module information is called module-info.java. The default directory structure is now extended to provide module support. So if you have module A com.foo.bar1 and module B with com.foo.bar2, they should be located in src/main/com.foo.bar1 and src/main/com.foo.bar2.
If you are using libraries that don’t have support for modules yet, JDK treats them as automatic modules. All classes are exported and all modules are required.
You should not create module-info.java on vendor libraries, since it is quite possible that it can conflict with the vendor’s module-info.java, once they have done the migration.
For starters there is the executable jdeps. It creates the module-info.java automatically.
There was a question concerning support for versioning. The answer was that modules are conceptually seen as a supergroup to packages and fall into the same category. As packages and classes don’t have versions, the same goes for modules.
The handling of versions is already solved by the common build tools like gradle or maven. So no need to compete with them.

Daniel Bryant: Continuous Delivery with Containers
In this talk Bryant presented some aspects and best practices in a continuous delivery setting where container technology plays an important role.
First of all he mentioned that CD (Continuous Delivery) does not mean that each commit has to be deployed. This is a misunderstanding.
One should keep the different environments - like dev, stage, production or test - as similar as possible. Using container technology gives you just that ability. In the special case of a test environment, where you might require an additional configuration, use the sidecar pattern instead of creating an own image.
An official Alpine Java image addresses the issue of size reduction of a typical Java container. Using JLink in combination with Java 9 modules, one can reduce the size of the jar. JLink removes all unused modules. Another reason to adopt Java 9 ;).
Bryant mentioned the Idea of having quality metadata on containers. It can be used to force certain security actions or executing tests on it. An example might be that, at a certain stage in the pipeline, only checked containers are allowed to move on.
Groovy can be used to write pipeline steps in Jenkins.
For performance and load testing, Gatling is a good choice.
He also emphasized the fact that we need to be more serious with security. Otherwise there is some risk that our whole industry gets regulated by the government. Use Clair to scan your images for security issues.
Very often non-functional requirements are delayed to the last moment. Simply put, this reduces the risk of over-engineering due to early performance optimisation. One should not take this is a rule. Sometimes it is good if non-functional requirements are taking into consideration up-front. Especially security.

Jürgen Höller: Spring Framework 5 - Themes & Trends
As co-founder of Spring and lead of the core framework, Jürgen Höller has quite a lot to say. Unsurprisingly the room was filled to bursting.
He mentioned that JDK 9 was not a long-term support release. Still one should definitely give it a try since there are many improvements over JDK 8. One can even use Spring 4.3 on JDK 9.
Spring 5 is already equipped with module definition files. So you don‘t need to rely on automatic modules. In version 5 the configuration can be done in an alternative functional style. So this is a further step after xml, annotation-based or Java Config approach. In the functional style we would have no classpath scanning and no internal reflection taking place.
The Reactor provides the basic foundation for the new reactive framework in Spring. The two main elements are Flux and Mono, where the latter means one or no element. Spring Webflux is based on Reactor, but is a complete and separate stack for the web. WebFlux works without the Servlet API. The known Web-MVC annotations like @Controller or @RequestMapping are supported on both stacks. WebFlux runs internally on Tomcat, Jetty, Netty or Undertow. Netty and Tomcat are recommended.
Additionally, there are so-called RouterFunctions where one can construct the routes functionally by passing a handler method to a defined route. It is useful if you have a lot of endpoints and you want to manage them centrally. As far as I understood this is only available for WebFlux.
Reactor is completely based on events (a pattern typical found in node.js) and has its own threads where the operations are running separately.
Also notable is a new WebClient that can act as client for WebFlux/Reactive endpoints. If you work with a MicroServices architecture, this is quite handy.
Höller ended his talk with the probably most important advice. If your datastore doesn‘t support reactive, don‘t even think about using it. Stick to good old classical MVC.
Brian Goetz: Java Language Futures - All Aboard Project Amber
Compatibility is one of the major concerns in Java. Amber is just one of many ongoing improvement projects and works to reduce the verbosity of Java. Its most important principle is that reading code happens more often than writing it. Therefore readability is Amber’s top priority.
The people behind Java are very conservative and are always very skeptical when adding features. Due to backwards compatibility and investment protection, they never want to remove them. They definitely don’t see themselves as first movers.
Type inference for local variables is planned for Java 10. Java already had type inference in version 5 for generic method type arguments. For example Collections<String>.emptyList() can be shortened to Collections.emptyList(). It isn‘t supported for method return type or field types because an API shouldn‘t have type inference.
A concept for data-only classes is still missing. Data-only classes can be compared to Case Classes in Scala or DataClasses in Kotlin. There are plans to support them.
Pattern Matching elevates the switch construct to become more readable. It will be joined by deconstructors, which can be used in the case parts. There is even support for nested pattern matching/deconstruction.
An example might be:
case Rect(Point(var x1, var y1), Point(var x2, var y2)) -> x1 + x2

